Eu, o Karpathy e o Google tivemos a mesma ideia

Era sexta-feira, 16 de janeiro de 2026. A Anthropic tinha lançado o Claude Cowork quatro dias antes, e eu queria testar. A ideia foi levar pro Cowork uma coisa que eu já vinha ensaiando no terminal do Claude Code: um sistema de gestão de caos que trabalhasse pra mim, e não o contrário. Eu estava soterrado de tarefas, com aquela sensação de que toda ferramenta que devia me ajudar exigia de mim tanto quanto eu dela.
Sem pretensão nenhuma, depois de umas duas horas, eu tinha uma v0. Batizei de Claudia.
Funcionou tão bem que, duas semanas e muitas versões depois, decidi que aquela gambiarra merecia virar uma coisa mais séria. E quando parei pra planejar como ela deveria ser, me ocorreu que nos últimos três anos, eu já tinha pulado do GPT pro Claude (e vice-versa) umas quatro vezes. Cada mudança doeu. Você conhece a sensação: a certeza sofrida de estar deixando suas coisas pra trás. Ideias, memórias, conversas que um dia, quem sabe, você fosse querer recuperar. Quase um vazio existencial.
Foi aí que decidi: Claudia tinha que ser agnóstica. Não podia depender de ninguém. E uma coisa que não depende de ninguém não pode carregar no nome a marca de um único modelo. Tive que rebatizá-la. Ali morreu Claudia e nasceu Prumo.
Pra começar, estabeleci algumas premissas. Poucas, mas inegociáveis. Cada uma vinha de uma cicatriz.
- Ser agnóstica. Nunca, em hipótese alguma, depender de um único fornecedor. Se amanhã a OpenAI estiver melhor que a Anthropic (ou a Anthropic ultrapassar todo mundo, ou aparecer um nome que ninguém ouviu falar ainda), eu quero trocar de cavalo sem deixar a sela pra trás.
- Ser simples e de baixa manutenção. Não é preguiça, é engenharia. Cada etapa a mais é um lugar a mais pra dar errado. MCPs são ótimos e falham a toda hora. Automações (Zapier, n8n e a turma) são geniais e falham sempre que um daqueles nós muda uma vírgula. Numa terça-feira atolada, às onze da noite, eu não quero descobrir que um webhook caiu. Quanto menos peças móveis, maior a chance de funcionar. Prumo tinha que ser mais ou menos como um caderno: você abre, e está lá.
- A terceira premissa é consequência das anteriores: tudo deve viver, essencialmente, em arquivos de texto no meu computador. Markdown, pastas, sem (necessidade de) nuvem, sem banco, sem tornar o usuário refém de ninguém. Se todo serviço de IA do planeta cair amanhã, 100% dos meus arquivos continuam ali, legíveis. Tudo meu.
- A última é menos uma premissa e mais o conceito que segura o resto de pé. O sistema não pode enxergar o usuário em fatias. Não há uma caixa para o profissional, outra pro pai e outra pro sujeito que precisa remarcar o dentista. Tem que ser a pessoa inteira, porque o seu cérebro não é um escaninho.
Cabeça é pra ter ideias, não pra guardá-las
Em 2001, no ótimo Getting Things Done, David Allen apresentou uma boa hipótese para a principal causa de estresse. Segundo ele, a cabeça é um péssimo lugar pra guardar pendência: ela esquece quando deveria lembrar e lembra no pior momento, bem quando você precisa se concentrar em outra coisa. O core da solução proposta por ele é uma caixa de entrada única, um lugar pra onde tudo converge e é processado. Nesse cenário, o alívio cognitivo não vem de ter todos os problemas resolvidos, mas de saber que tudo, de todas as áreas da sua vida, está num lugar confiável, e que nada importante vai escorregar. E aí a cabeça fica livre pra fazer o que ela faz bem, que é pensar, em vez de passar o dia cuidando de to-do list.
Faz mais de 20 anos que tento aplicar esse método à minha vida. Ele é ótimo, exceto pelo fato de que, em 2001, ainda não havia um agente de IA pra cuidar da caixa.
Conceito fechado: Prumo deveria ter uma caixa de entrada única pra processar. E a partir daí, deveria estar sempre bem informado.
Picar o conhecimento em pedacinhos
A forma mais difundida para se dar memória a uma IA hoje é o RAG. A IA fragmenta todo o conhecimento em pequenos chunks e, quando precisa resgatar algo, busca nesses pedacinhos. RAG viabiliza buscas em grandes acervos sem estourar a memória de trabalho da IA, mas isso tem um preço: sempre há perdas no processo.
No longínquo ano de 2024, era o que havia de melhor. Mas hoje, quinze anos dois anos depois, os modelos, as camadas e ferramentas em volta deles evoluíram a ponto de tornar o RAG obsoleto em muitos casos de uso (não, eu não odeio RAG. Sim, ele faz sentido em algumas ocasiões). Há um segundo problema: numa troca de sistema, todos aqueles chunks precisariam ser recriados. Não chega a ser um grande lock-in, mas já é o suficiente pra desanimar.
Embaraçosamente simples
A aposta do Prumo é a oposta: não fragmentar nada. A arquitetura se baseia em documentos Markdown inteiros que operam no conceito de "descoberta progressiva" (o mesmo das skills): o agente lê o primeiro (CLAUDE.md/AGENTS.md da raiz do meu workspace) e, a partir daí, há índices que o guiam por todo o meu universo.
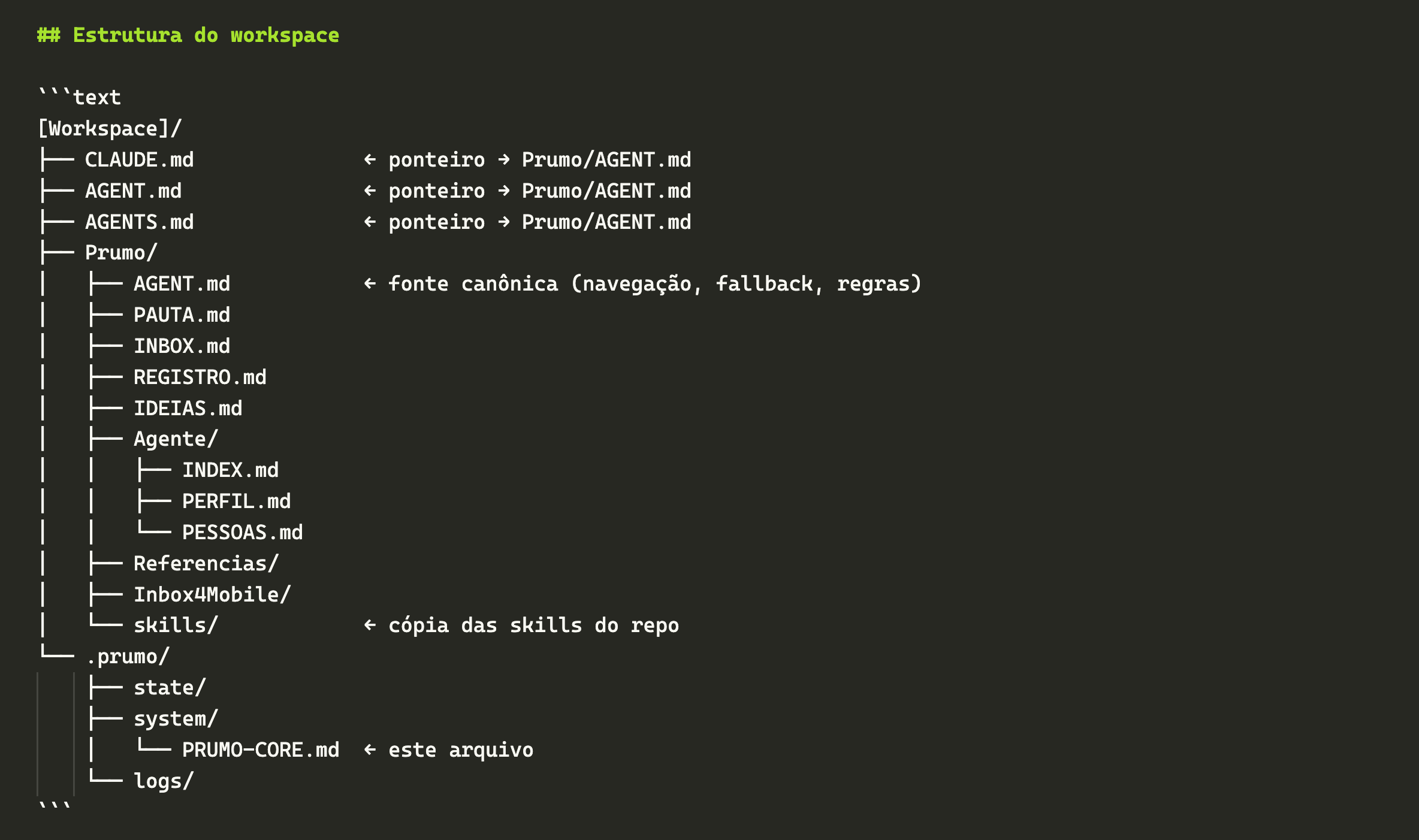
Desde antes de existirem "skills" como a gente conhece hoje, eu já vinha fazendo a coisa de forma meio intuitiva no Claude Code. Largava arquivos MD (ou txt mesmo) pelos cantos e pedia ao agente que os lesse antes de trabalhar. Funcionava, mas era artesanato. Quando as skills viraram padrão de verdade, e os modelos passaram a ser treinados pra trabalhar com elas, deu match.
A arquitetura põe o contexto a serviço de um pequeno arsenal de skills e workflows: quando eu abro um agente pela manhã e digo 'Prumo', ele processa tudo o que caiu na caixa única desde ontem e me conta o que o dia reserva. Não só o trabalho. Tudo. O boleto que vence, a ligação que prometi retornar, o presente que esqueci de comprar, a tarefa que deixei pela metade, a outra que já empurrei três vezes e que ele não me deixa fingir que esqueci.
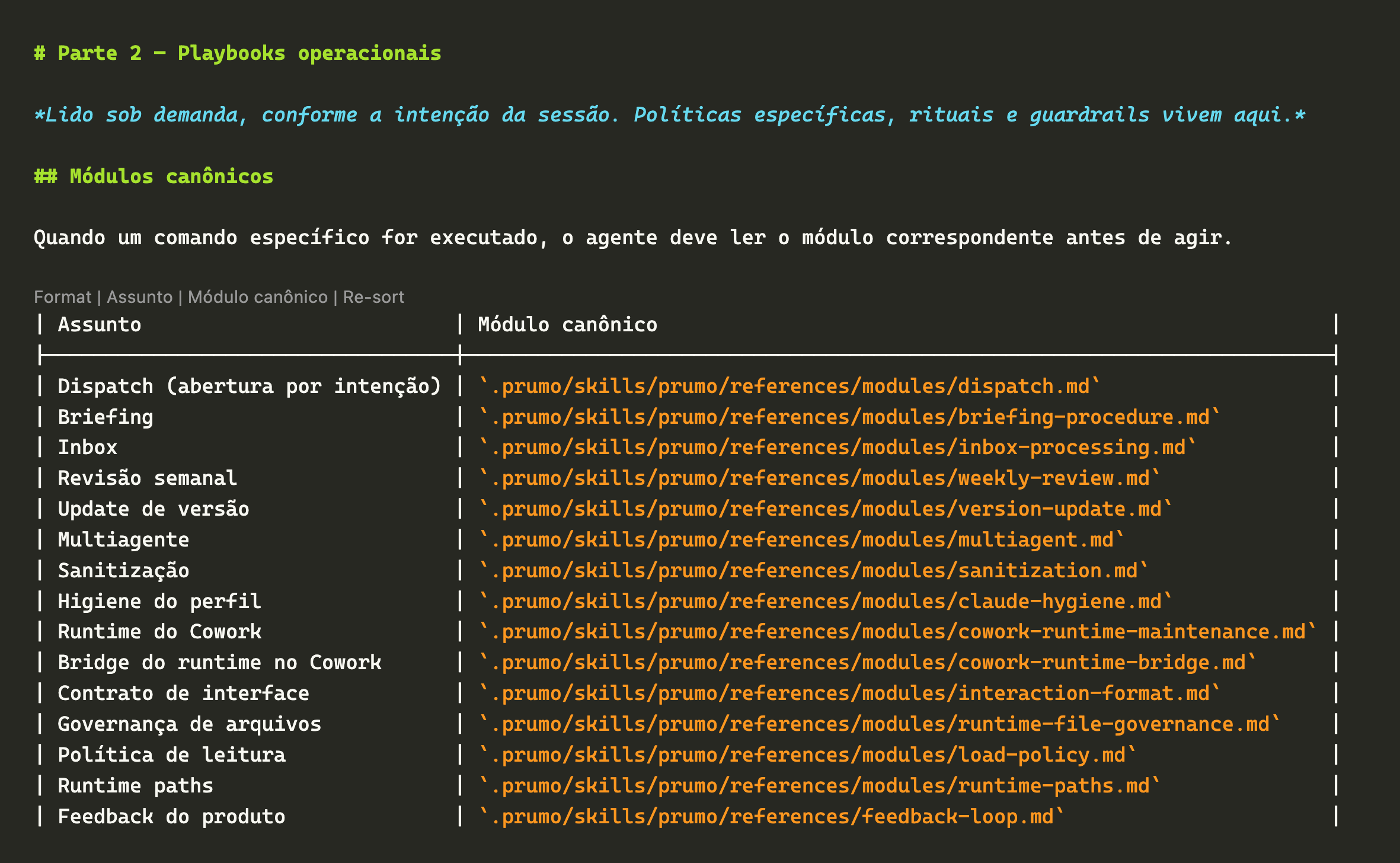
E entra de qualquer canto: email, uma nota digitada às pressas, um print, um atalho de compartilhamento no iOS/macOS que eu disparo do celular esperando o café ficar pronto. A caixa é única; as portas de entrada, várias.
E como ele documenta o que acontece em tempo real, tenho sempre o conforto de estar conversando com alguém que conhece as minhas falhas, o contexto de cada pendência, as preocupações, as pessoas que estão à minha volta e até os meus padrões recorrentes.
A diferença para uma lista de tarefas comum é grande: a lista é estática, passiva. O Prumo, além de te entender, ainda ajuda a fazer o trabalho.
E todas essas coisas estão registradas em arquivos de texto que qualquer agente consegue ler. Claude Cowork, Claude Code, Codex e Antigravity leem os mesmos arquivos e se revezam sem se atropelar — coordenados por um singelo 'agent-lock.json'.
Sempre que algo entra, sai ou muda, o agente registra. Toda vez que um desses documentos de referência ultrapassa um certo limite de tamanho, o sistema dispara uma sanitização que identifica o que é lixo, o que deve ser catalogado e já faz o serviço automaticamente. No caso de o documento inchado ser de conteúdo, Prumo sugere ajustes mas aguarda a minha aprovação.
No fim, funciona inacreditavelmente bem. Apesar disso, noto que a simplicidade do Prumo desperta uma certa desconfiança. Eu entendo. Com tanto Pinecone, PageIndex e GraphRAG por aí, custa acreditar que um modelo de IA, meia dúzia de ferramentas e arquivos de texto se saiam tão bem. A questão é que esses caras resolvem outro tipo de problema — busca em acervos gigantescos. E eu criei uma ferramenta pra resolver só o meu caos.
O plot twist Karpathy
Em abril, o Andrej Karpathy (ex-Tesla, ex-OpenAI, o cara que ensinou meio mundo a treinar rede neural e hoje é a pessoa mais badalada da Anthropic depois do Dario Amodei) publicou um gist curto intitulado "LLM Wiki" propondo, em quase tudo, a mesmíssima lógica do Prumo.
Nas palavras dele:
Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent wiki — a structured, interlinked collection of markdown files that sits between you and the raw sources. (...) You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it. You're in charge of sourcing, exploration, and asking the right questions. The LLM does all the grunt work — the summarizing, cross-referencing, filing, and bookkeeping that makes a knowledge base actually useful over time.
E, na semana passada, foi a vez do Google dar à luz o OKF (Open Knowledge Format). Nas palavras deles:
That's why today, we're introducing the Open Knowledge Format (OKF), an open specification that formalizes the LLM-wiki pattern into a portable, interoperable format. This is a vendor-neutral, agent- and human-friendly standard for representing the metadata, context, and curated knowledge that modern AI systems need.
E não é coincidência que soe familiar: no mesmo anúncio, o Google aponta o gist do Karpathy como a articulação mais nítida da ideia.
Mesma coisa. Pastas, arquivos markdown, um campo 'type', um índice, links entre as notas. Os três navegam igual, inclusive: um índice que o agente abre nível a nível — a descoberta progressiva de sempre. Mas, no caso do Google, tem uma pegadinha sutil: o formato é aberto, mas o produtor de referência puxa do BigQuery e enriquece com Gemini. Formato aberto, motor de enriquecimento proprietário. Dar o mapa de graça também é um jeito de vender a picareta. Não é uma crítica, esse é o negócio dos caras.
E o mais engraçado é que nunca teve nada de sofisticado aqui. O Prumo é a caixa de entrada do David Allen casada com a wiki do Karpathy, num só lugar de texto puro — capturar e lembrar deixaram de ser duas tarefas separadas.
Resumo da história: um dos pesquisadores de IA mais relevantes do mundo e o Google copiaram a minha ideia. Hahahaha... brincadeira. Mas o timing é cômico: o Karpathy publicou a ideia dele em abril e foi trabalhar na Anthropic em maio. Alô, Anthropic, olha eu aqui! Brincadeiras à parte, me deu um quentinho no coração. É bom saber que não tô maluco. Ainda.